Overview
 The Database Destination Component is an SSIS Data Flow Component for loading and updating data into a database table. The component can be configured to insert, update, delete or upsert in row-by-row or bulk-load mode for ADO.NET, OLE DB and ODBC connections (see a list of supported databases below). Custom setup and teardown logic is supported via optional pre and post execute SQL commands. Error redirection is available in row-by-row mode and for ODBC bulk-load.
The Database Destination Component is an SSIS Data Flow Component for loading and updating data into a database table. The component can be configured to insert, update, delete or upsert in row-by-row or bulk-load mode for ADO.NET, OLE DB and ODBC connections (see a list of supported databases below). Custom setup and teardown logic is supported via optional pre and post execute SQL commands. Error redirection is available in row-by-row mode and for ODBC bulk-load.
The availability in version 2.0 of the Database Destination Component makes obsolete the following SSIS+ destination components:
- ODBC Destination
- Oracle Destination
- DB2 Destination
- Informix Destination
- Sybase Destination
- Teradata Destination
Supported databases
The component allows usage of three kinds of database connections - ADO.NET, OLE DB and ODBC. Most of them support an optimized bulk-load mode, all support the regular row-by-row data processing.
| Database | ADO.NET | OLE DB | ODBC | Speed |
|---|---|---|---|---|
| SQL Server | regular and bulk | regular and bulk | regular and bulk | |
| Oracle | regular and bulk* | regular | regular and bulk | 10-30x |
| Teradata | regular | regular | regular and bulk | 80x |
| PostgreSQL | regular and bulk | - | regular and bulk | 10x |
| DB2 | regular and bulk | regular and bulk ** | regular | 20x |
| MySQL | regular | regular | regular and bulk | 30x |
| Informix | regular and bulk | regular | regular | 6-8x |
| SAP ASE | regular and bulk | - | regular and bulk |
* The bulk load is supported only with ODP.NET, Unmanaged Driver.
** The bulk load is supported only with Microsoft OLE DB Provider for DB2.
Editor
General Page
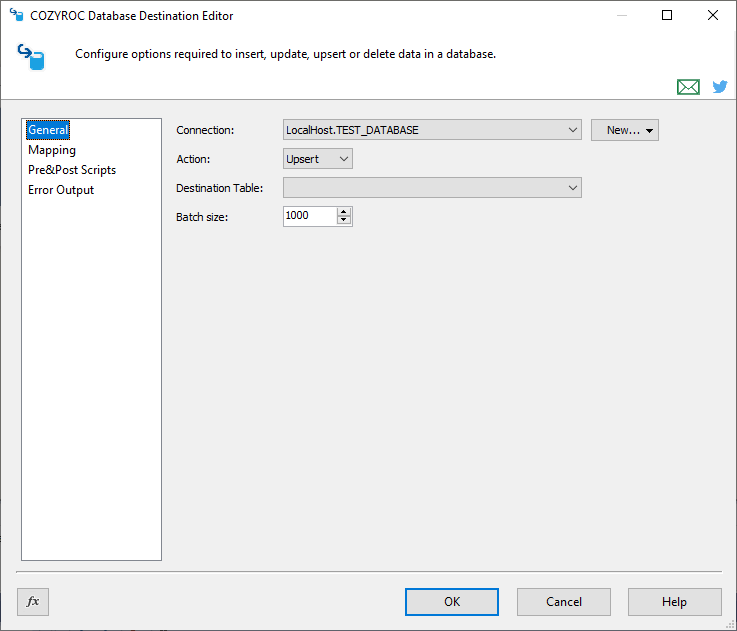
In this page the general parameters are configured.
Mapping Page
The page allows detailed mapping for each part of the database statement. Depending on the Action a database statement can have maximum three parts - Insert, Update and Match. The page shows mappings tabs according to the selected Action. This allows to specify exactly which columns will be used in each part of the statement. For example when the Action is Upsert, the user can insert all columns and update a few of them. The separated mappings can be used even to update a Primary Key.

In this tab the mappings for the insert part are configured. The tab is visible when the Action is Insert or Upsert.
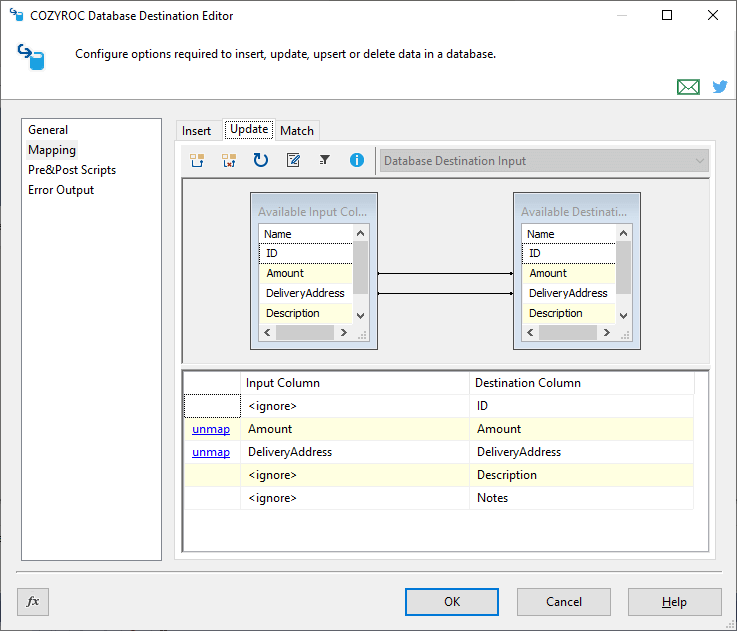
In this tab the mappings for the update part are configured. The tab is visible when the Action is Update, Upsert or Merge.
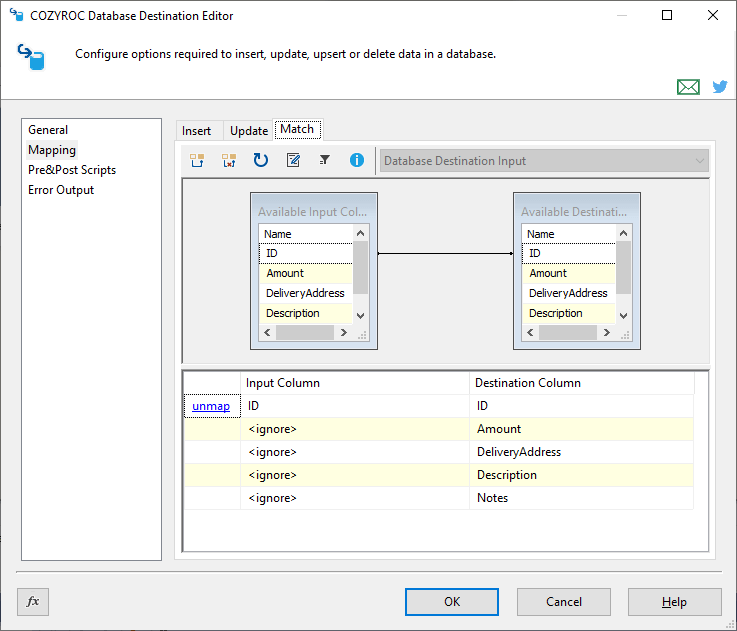
In this tab the mappings for the match part are configured. The tab is visible when the Action is Update, Delete, Upsert or Merge.
Pre&Post Scripts Page
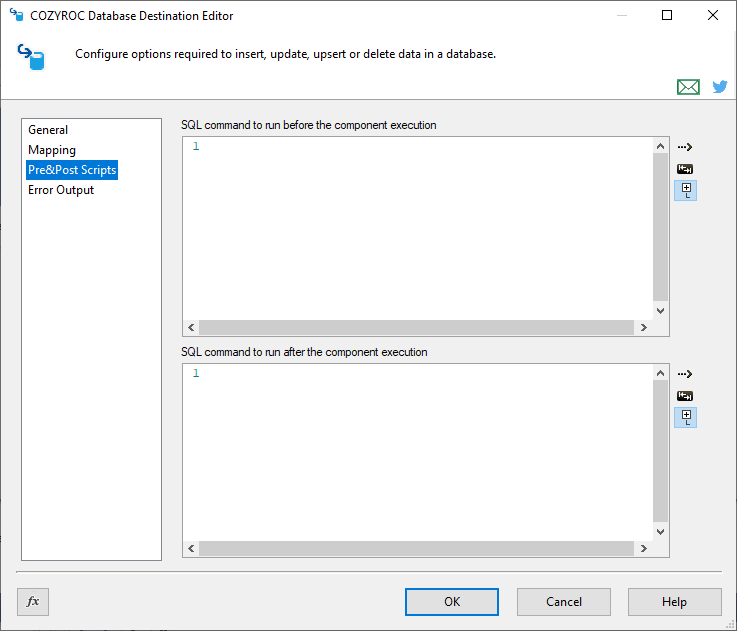
In this page the pre and post execute SQL commands are configured.
Merge
When running in SQL Server bulk mode, the component provides an additional Merge action, which performs an Upsert and deletes missing rows to fully synchronize the target with the source.
Results
Since version 2.2, the component is providing result information in one or two Result Outputs. All of the fields of the destination table are columns of the Result Outputs. The type of Action determines the availability of result outputs:
-
Insert
"Inserted Records Output" contains the field values of the inserted rows. It includes also the values that are populated automatically by the DBMS (e.g. identity fields).
-
Update
"Updated Records Output" contains the old and the new field values of the updated records.
-
Upsert
Supports both "Inserted Records Output" and "Updated Records Output" outputs (see above).
-
Delete
The "Deleted Records Output" contains the old field values of the deleted rows.
-
Merge
Supports "Inserted Records Output", "Updated Records Output" and "Deleted Records Output" outputs (see above).
Efficient batch operations
When batch mode is enabled (i.e. when the batch size is specified to a number > 1), an automatically created temporary table is used to speed up the processing. Data is bulk inserted in this table and then the destination table is updated depending on the selected action with a one or more SQL commands. The temporary table is removed in the post-execute phase.
Please note:
Oracle bulk mode can be used only with the ODP.NET, unmanaged driver. It doesn't allow update of a column used in the match part of the statement because of the Oracle MERGE statement limitations.
PostgreSQL ODBC bulk mode is array insert. When complex types are used the loading speed will be slower. Each additional complex column will slow down further.
DB2 ODBC bulk mode is array insert. DB2 OLE DB bulk mode is supported only with the Microsoft ODBC Driver for DB2, the driver doesn't support the field types: LONG VARCHAR FOR BIT DATA, VARGRAPHIC, XML and DECFLOAT.
SAP ASE ADO.NET driver supports bulk-load only in an empty table. An intermediate automatically created temporary table is used. Rows are bulk-loaded in a temporary temp table, then they are transferred to the destination table using SQL command. The temporary table is removed in the post-execute phase.
SAP ASE ODBC bulk mode is array insert when the table has an identity column.
Identity Insert
SQL Server and SAP ASE permits inserting value in an identity column. SAP ASE permits updating an identity column. When the destination table has an identity column these modes are supported. Need to be explicitly enabled with the Identity Insert option.
Temporary table schema and database
In Bulk mode, when the Action is Update, Delete, Upsert or Merge, a temporary staging table is used, and by default it is created in the destination table schema.
The database and/or database schema of the staging table can be customized via the property TempSchema. It accepts either a schema or a combination of database + schema. E.g. specifying TempDatabase.dbo for SQL Server will instruct to use a temporary table in a database TempDatabase and schema dbo.
Please note that some databases like DB2 need special configuration to use more than one database in a single SQL statement.
Enabling triggers and other settings with bulk inserts
By default triggers won't fire during a bulk insert, but the firing can be enabled for OLE DB driver and for SQL Server ADO.NET driver. To enable triggers the property FastLoadOptions should contain value FIRE_TRIGGERS.
For OLE DB drivers you can specify in FastLoadOptions property additional settings. Check available options for the SSPROP_FASTLOADOPTIONS property here.
Remarks
PostgreSQL ADO.NET support requires installation of the Npgsql ADO.NET Data Provider for PostgreSQL.
Because of a bug in SAP ASE ADO.NET driver unsigned smallint, unsigned int, unsigned bigint and smallmoney field types cannot be used.
When used SAP ASE ODBC driver decimal or numeric field types are not working. We have sent the following incident cases: 11553913, 11553762, 11553757.
Tested Databases
As of now, the component has been tested with the following databases (depending on database version compatibility, it will work on previous and future versions):
- SQL Server 2017
- Oracle 18c
- Teradata Express 16.20
- PostgreSQL 12.3
- IBM DB2 11.5
- MySql 8.0
- IBM Informix 14.10
- SAP ASE 16.0

Demonstration
Quick Start
In this quick-start we will setup Database Destination to make upsert in a database table. Bulk-copy mode will be used with the default batch size of 1000 rows.
To try upsert you can use the demo package from this archive. You should create a TEST_TABLE table with the following columns (the archive contains script to do that) :
- ID
INT - DEALDATE
DATETIME2 - PRICE
FLOAT - DESCRIPTION
NVARCHAR2 (250) - AMOUNT
DECIMAL (16)
The NumberOfRows variable controls the number of rows used in the insert and in the upsert phase
Select connection
Let's start by selecting an existing ADO.NET, OLE DB or ODBC connection manager. To use bulk-mode the connection manager must support it.

Select action
Select Upsert action.

Select table
We will use the dbo.TEST_TABLE.

Map columns for insert
Go to the Mappings page Insert Tab to confirm automatically created mappings. Mapped columns in this tab will be used only for insert.

Map columns for update
Go to the Mappings page Update Tab. Initially all columns will be mapped. Unmap the ID column, it is used as a Primary Key. Mapped columns in this tab will be used only for update.

Map columns for the condition
Go to the Mappings page Update Tab. No columns are mapped automatically here. Map the ID column. Mapped columns in this tab will be used only in the statement condition.

Parameters
Configuration
Use the parameters below to configure the component.
Select an existing ADO.NET, OLE DB or ODBC connection manager.
Related Topics: ADO.NET Connection Manager, OLE DB Connection Manager, ODBC Connection Manager
Specify the desired action. This parameter has the options listed in the following table.
Action Description Insert Insert new rows in the destination table. Update Update rows matching primary key in the destination table. Delete Delete rows matching primary key in the destination table. Upsert Update rows matching primary key, insert non-matching in the destination table. Specify the destination database table where the data is loaded, updated or deleted.
Specify the number of rows to be sent as a batch. If the size is set to 1, the component uses regular insert.
Specify the number of seconds allowed for the operation to complete before it is aborted.
Specify if Identity Insert or Identity Update should be allowed. The table must have identity column. Identity Insert is supported on SQL Server and SAP ASE. Identity Update is supported on SAP ASE.
Specify how to handle rows with errors.
Controls the handling of NULL values in SQL Server bulk operations.
When set to False (default): The destination table's column default values, if any, are used instead of NULL. The user must have VIEW DEFINITION permission on the table.
When set to True: NULL values are written to the destination table.
What's New
- New: Ability to alter table or create an entire table with metadata from upstream component when running in Data Flow Task Plus.
- New: Improved bulk-load performance when using OLEDB connections. The performance is now better compared to the standard OLE DB Destination component.
- New: Improved bulk-load performance when using ODBC connections.
- New: Support for MERGE action in SQL Server database.
- Fixed: Running out of memory when using OLE DB driver (Thank you, Joseph).
- FIxed: Crash in dynamic flow context, in case not all input columns are used.
- New: Support for Oracle Provider for OLE DB bulk API.
- New: Ability to customize match clause.
- Fixed: (ODBC) Failed with error "SQLBulkOperations(SQL_ADD) ERROR:Invalid input syntax for type numeric: """ when trying to insert NULL value into column of type NUMERIC(28,10) (Thank you, Gustavo).
- New: A new parameter FastLoadOptions to configure additional bulk-load features like trigger firing.
- Fixed: Unable to process input columns of type DT_DBTIME2 when using OLEDB driver (Thank you, Kelsey).
- New: Improved support for IBM DB2 iSeries when using the ODBC driver.
- Fixed: (ADO.NET) failed with error "Cannot resolve the collation conflict between "SQL_Latin1_General_CP1_CI_AS" and "SQL_Latin1_General_CP1_CS_AS" in the equal to operation." (Thank you, Kelsey).
- Fixed: Issue with SQL Server matching NULL values in Update, Upsert and Delete mode (Thank you, Christopher).
- New: Enhanced input columns mapping and configuration (Thank you, Mika).
- Fixed: Failed with error "Invalid object name 'SYS.OBJECTS'" when using a case-sensitive database (Thank you, Annette).
- Fixed: Insert failed in the temporary table with identity column (Thank you, David).
- Fixed: Failed with error "Incorrect syntax near the keyword 'MERGE'" on machines with older driver (Thank you, Josh).
- Fixed: Destination table columns are no longer alphabetically sorted when initialized (Thank you, Mika).
- Fixed: Columns refresh overview displayed incorrect information (Thank you, Geoff).
- Fixed: Failed with error "System.Collections.Generic.KeyNotFoundException: The given key was not present in the dictionary." when trying to process a destination table found in a schema different from
dboschema (Thank you, Ayman). - New: Improved handling of columns of type datetime2 when using OLE DB driver (Thank you, Damien).
- New: A new parameter TempSchema to configure the schema for the used temporary tables.
- New: Improved error diagnostic information when using DB2 database (Thank you, Mika).
- Fixed: Failed to initialize the default value for columns of type BIT in MySQL (Thank you, Sundar).
- Fixed: Errors when destination SQL Server table contains UDT columns (Thank you, Alain).
- New: Introduced component.
Related documentation

COZYROC SSIS+ Components Suite is free for testing in your development environment.
A licensed version can be deployed on-premises, on Azure-SSIS IR and on COZYROC Cloud.